
是的,当大家都还在折腾龙虾时候,我关注的是MiniMax M2.7, 很多还没注意到一个事前,养龙虾的根部问题不是龙虾本身,而是喂的饲料,所以很多人都觉得不就是喂Token吗,花钱就是了,这就已经说到问题本质了 ,饲料怎么选很重要,如果从真实使用强度来看,MiniMax M2.5 在 OpenRouter 上的表现,已经不是“热门模型”,而是典型的“流量吞噬者”。2026年2月至3月,多项第三方统计与社区榜单均显示,其 token 调用量连续多周位居前列,并稳定处在“万亿级/周”的消耗区间。换句话说,在开发者生态里,M2.5 很可能是当下最典型的“喂token机器”。相比之下,无论是 Kimi 还是 DeepSeek,更偏向能力或场景优势;而 M2.5,则是在“成本 × 吞吐 × 可持续调用”这一维度上,把规模效应推到了极致。

所以需要来深度了解下,先把公司底子说清楚,避免大家云里雾里,MiniMax 全称 上海稀宇科技有限公司(部分报道也写成上海稀宇极智科技有限公司),总部位于上海徐汇区模速空间。创始人闫俊杰(曾参与商汤科技计算机视觉项目)带着团队2021-2023年间正式起航,主打“与所有人共创智能”。 早期靠 abab系列 + 多模态(视频Hailuo、语音Speech、音乐Music)出圈。2023年8月abab大模型通过国家首批备案,2024年推出abab 6.5系列,2025年发布Hailuo 02视频模型,估值一度破百亿港元,2026年1月已在港交所上市(股票代码00100.HK),市值最高冲到3000亿+港元。 但真正让MiniMax从“视频生成公司”变成Agent黑马的,是2025年开始的 M系列文本大模型。他们押注的不是单纯的聊天或生成,而是生产力+Agent+自我进化。M2.7就是这个战略的巅峰产物——官方直接说:“M2.7是我们第一个模型深度参与迭代自己的模型。”一句话总结公司定位:中国版“全栈Agent原生AI公司”。不像某些大厂只做聊天,它从底层架构到应用层(MiniMax Agent APP、开放平台)全闭环,目标是把AI变成每个打工人的“超级助手+团队”。
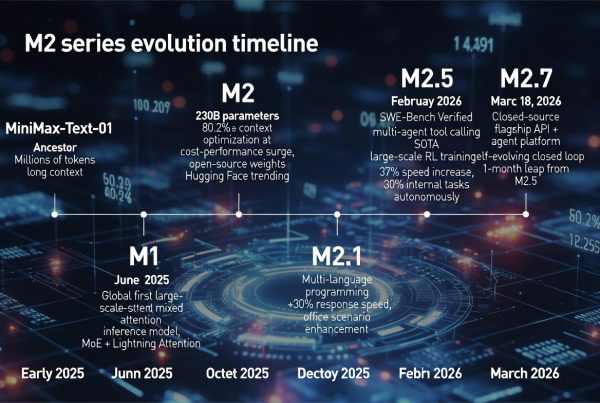
M2系列进化史:M2.7不是突然冒出来的,M2.7的诞生,也是一步一个脚印的“进化链”:
2025年初:MiniMax-Text-01(M系列祖先)——百万token长上下文,打基础。
2025年6月:M1——全球首个大规模混合注意力推理模型(MoE+Lightning Attention),正式开启Agent时代。
2025年10月:M2——Agent原生模型,230B参数,上下文优化,速度/性价比暴增,开源权重刷爆Hugging Face。
2025年12月:M2.1——多语言编程、响应速度+30%,办公场景加强。
2026年2月:M2.5——编程SWE-Bench Verified 80.2%,多Agent工具调用SOTA,引入大规模RL训练,速度再提37%。此时已能让公司内部30%任务自主完成。
2026年3月18日:M2.7——闭源旗舰(API+Agent平台调用),自我进化闭环正式上线。距离M2.5仅1个月,却完成质变。
官方原话:“在M2系列发布后的几个月,我们收到大量用户反馈……唯一途径就是开启模型和组织的自我进化。”于是,他们用早期M2搭建“Agent Harness”(智能体外层脚手架),让模型自己参与实验设计、日志分析、debug、调参、代码提交……循环100+轮,内部评测提升30%!M2.7参数约229B,上下文20万+ token,API定价亲民(highspeed版输入4.2元/百万token),现在已在 MiniMax Agent APP(iOS/Android/桌面版)和agent.minimaxi.com全量上线。

亮点1:多智能体组队干活,模型自己当“团队指挥”
M2.7 让模型智能体写作能力, 不是靠外部编排框架,而是自己带队干活,也会自我进化,MinMax内部做过个疯狂测试,让模型自己当架构师,仅靠一个人类,花了4天时间,0行人工代码,就搭出来一整套研发系统,它甚至自己跑去参加机器学习竞赛,一口气拿下了9枚金牌,过去需要一个团队协作的实验,现在M2.7自己就干掉了一半工作量,以前Agent协作靠外部框架(LangChain/CrewAI)硬堆,角色容易崩、沟通乱。M2.7直接原生内置Agent Teams:它自己定义角色边界、执行对抗式推理、遵守协议。
基准数据:GDPval-AA ELO 1495分(开源最高,仅次于Opus 4.6/Sonnet 4.6/GPT-5.4)。实测表现:一个Agent写代码、一个review、一个测试debug,互相challenge逻辑盲点。40+复杂技能(每个>2000 tokens)遵守率97%。
场景:写一个完整SaaS产品,它能拆成“产品经理Agent+前端Agent+后端Agent+测试Agent”,自主协作交付。官方说,这把开发效率提升到“范式级”。
亮点2:编程能力从“写代码”进化到“修生成事故”——SRE级别
以前模型只会生成代码,现在M2.7是生产环境全能战士。
收到线上告警后,它能:
关联监控日志 → 根因分析(调用链+数据库查询)
数据库调优(发现漏索引 → 非阻塞建索引止血)
代码修复+提MR+冒烟测试
故障决策(优先级+回滚方案)
基准:
SWE-Pro:56.22%(接近Claude Opus最佳,匹配GPT-5.3-Codex)
VIBE-Pro(端到端项目交付):55.6%
Terminal Bench 2(复杂工程系统理解):57.0%
真实案例:官方演示中,线上故障恢复时间缩短到3分钟,研究员介入率降到30-50%。它现在更像SRE(站点可靠性工程师)+ DevOps,而不是单纯coder。社区有人说:“以前写代码是基本功能,现在它直接帮我值夜班了。”
亮点3:数字化办公,拯救Excel恐惧症 + 高保真多轮编辑
这可能是最贴近打工人的杀手级能力,M2.7深度支持Office三件套:
Excel:金融建模、脏数据清洗、多轮修改(公式、透视表、图表自动生成)
Word:结构调整、语言润色、高保真修订
PPT:模板生成+交互编辑,直接输出可编辑文件
基准:GDPval-AA ELO 1495(专业知识+任务交付SOTA)。
实测:能读年报→比对竞品→建预测模型→出Excel图表+Word报告+PPT汇报。
多轮高保真:你改一句,它保持格式/公式/布局不变。
一句话:把“高级Office技能”变成了每个打工人的默认配置。财务/咨询/运营岗直接起飞。
亮点4:角色扮演 + 赛博养宠,人格化陪伴新高度
M2.7情商和身份保持能力大幅提升,支持10种语言跨语言人格统一 + 长期记忆框架。亮点在于:闲聊陪伴不OOC,互动小说/沉浸游戏,多角色群聊:多个Agent自主互动,“赛博养宠”:赋予持久身份、真实情感厚度(记住过去对话、情绪演变),因为Agent能力内化了长期一致性。社区已经有人用它建“虚拟伴侣”或“多角色故事宇宙”,反馈人格厚度完胜以前模型。
所以,回到最开始那句话。当所有人还在讨论“龙虾好不好养”“一只龙虾要喂多少Token”的时候,其实问题早就偏了。真正决定你能不能跑起来的,从来不是龙虾本身,而是你喂它什么饲料——是碎片化调用、一次性对话,还是持续、高强度、结构化的任务投喂。
你以为你在用模型,其实你只是在“偶尔喂一下”;而真正跑出规模效应的人,已经在把模型当成生产系统,甚至是组织的一部分。这也是为什么,像 MiniMax M2.5 会变成“流量吞噬者”。它不是最会说话的,但它是最能被“持续喂养”的。而 M2.7,更进一步——
它不只是吃饲料,它开始参与生产饲料,甚至开始优化自己的进食方式。这才是这波变化真正可怕的地方。很多人以为,这一轮AI竞争,是模型能力的竞争;但慢慢你会发现,它其实变成了:
谁能构建一个可以持续投喂、持续迭代、持续放大的系统。

小龙虾只是表象,Token只是成本,模型只是载体。同样一个复杂任务,不同模型的成本差距,并不体现在“每次调用贵不贵”,而在于“要走多少轮”。
有的模型需要反复试错、修正路径,兜兜转转消耗掉10万token;
而具备更强Agent能力的模型,能一次拆对任务、减少无效调用,把总消耗压缩到1万token级别。这不是简单的价格差异,而是“推理路径效率”的差异。
真正的分水岭,是你有没有意识到——你是在“用工具”,还是在“搭一个会自己长大的系统”。当这个认知出现之后,才是M2.7真正指向的方向,从某种程度上说,小龙虾的出线不光是卷了打工人我们普通老百姓,同样也是在卷上层,在高频调用和持续投喂的场景下,模型之间的差距被无限放大——成本、吞吐、稳定性,开始决定生死。这也是为什么,这一轮AI竞争,看起来是在比模型,实际上是在比谁更适合被长期运行。




