
过年了,本来以为是个很轻松的平常的春节,公司这边刚放假,家里也开始准备过年的,结果就在最近几天突然,DeepSeek又一次出现在我眼目前了,本来几周前也用过了,就觉得很智障的一个玩意,没想到突然又出现了,我原来想着是录个视频给一顿说道,后来想想,算了吧,有些事让子弹飞一会就好了,但还是做了一些相关的记录吧,就是纯个人认知上的一个记录,不喜勿看!
过年穿新衣
Deepseek过年期间不管是科技界,还是金融领域到底做了什么,这么让人瞩目?因为他足够的低成本足够的高效!
成本有多低?
时间成本:我们的deepseek前身是幻方量化一家金融性质的公司,到2023年7月份转投AI领域,创办了Deepseek公司,仅用一年半左右时间研发,就缔造了一个,可以匹敌全世界最牛的从2015年就开创的openAi公司的不断更新迭代的人工智能模型deepseek,时间成本只用了人家1/20!
人员成本:Deepseek 加上老板一共139人,OpenAi 研发人员1200人,厉害啊,人员成本只有人家的1/10!
研发投入资金:Deepseek 研发资金是558万美元,OpenAi 单单一个4o阶段研发费用高达7800万美元,厉害吧,又是1/10!
研发训练:那是我们不分昼夜计算机训练?我们计算机比美国人的计算机更有牛马精神,肯定不是啊,我们deepseek 只用了2048块H800GPU显卡,训练60天就可以了合计是278万个GPU小时,openAi呢,英伟达老黄说过,光4o阶段,8000块H100(比H800性能高出一倍,为啥不用Deepseek不用高级H100,因为H100被禁用了)训练90天,合计1728万个GPU小时, 278对1728,又只用了别人约1/6的训练时间就成功了!
综合说来:Deepseek 用了全世界最牛逼人工智能OpenAi公司的不到1/20 的研发时间,1/10的研发人数,1/10的研究资金,1/6的模型训练成本,就搞出来了可以超越别人的高科技人工智能!而且免费开源,就是交个朋友!这种事情,如果不是和美国人全世界最厉害的成功科技产品对标,放到普通行业产品里对比,那无疑就是在诈骗!
打个比方:你要买有一套别墅,通常过程是开发商要花钱买地,承建公司盖房,要招聘很多建筑工人,花费了好几年时间,把别墅搞好了价值800万! 但是结果对面一家新开发商(以前炒股做量化投资的),告诉你只要注册个会员,就可以马上入住你心仪的房子,你问他们盖的房子买地花了多少钱,他们说就花了100块;问他们盖了多久,他们说1个月就盖好了;你问他们有多少人参与施工,他们说10个工人就够了!能住,还不收钱,就是交个朋友!你会怎么想?你觉得事实会发生吗?
那么deepseek到底是怎么办到呢?
目前看说法最多的是:数据蒸馏
目的是将复杂模型的知识提炼到简单模型。这一想法是通过已有的高质量模型来合成少量高质量数据,作为新模型的训练数据,从而达到接近于在原始数据上训练的效果。
伦敦大学学院(UCL)名誉教授和计算机科学家彼得·本特利在接受每经记者采访时表示:“这可能会对小机构的(研究)进展产生重大影响,这些机构不像OpenAI或谷歌那样拥有巨额预算。”
但这并不意味着,蒸馏技术就是一个十全十美的事物。王汉卿向每经记者表示,“我认识的(一线研究人员)基本没人搞(蒸馏)了。”目前优化大模型的方法是量化,比如降精度或是降缓存。DeepSeek-V3的技术报告也提到了使用FP8混合精度训练框架降低进度和通过压缩键值来降低缓存的方法。 据他解释,蒸馏技术存在一个巨大缺陷,就是被训练的模型(即“学生模型”)没法真正超越“教师模型”。早在2015年,诺奖得主杰弗里·辛顿(Geoffrey Hinton)就提出了蒸馏(Distillation)这一思想,可以讲压根就不是什么新鲜玩意!只是现在没人去用了!因为有研究表明,通过蒸馏训练的模型总是受到其“教师模型”能力的限制,这会产生一种隐性天花板效应,无论蒸馏过程多么复杂,都无法真正超越原始模型的能力。当考虑到需要将能力扩展到新领域或应对以前从未见过的挑战时,这种限制就愈发成为问题!
现在知道了大概情况了,那再看看deepseek相关背景吧:
金融圈里的业内描述幻方量化是这样的:一堆数学物理计算机博士,放弃了研究火箭,量子力学,战斗机的机会,去大A炒股,结果干碎了一批又一批正经金融科班出身的相关从业者!
那么他们在股市金融这块口碑如何?算了,这块我就不去戳大A股民的痛点了!稍微炒股几年或者在金融领域从业的都知道,网上也有,不过估计这会应该被删除了很多,毕竟现在满屏都是溢美之词!
这件事如果写到这就没了,那是我不负责的发表内如,所以我把自己用之前和28号使用chatGPT和Deepseek用相同的问题,做了对比,并且贴出来大家看下就知道了:
刚 注册使用的时候,我是问了一个及其简单的数值大小问题:
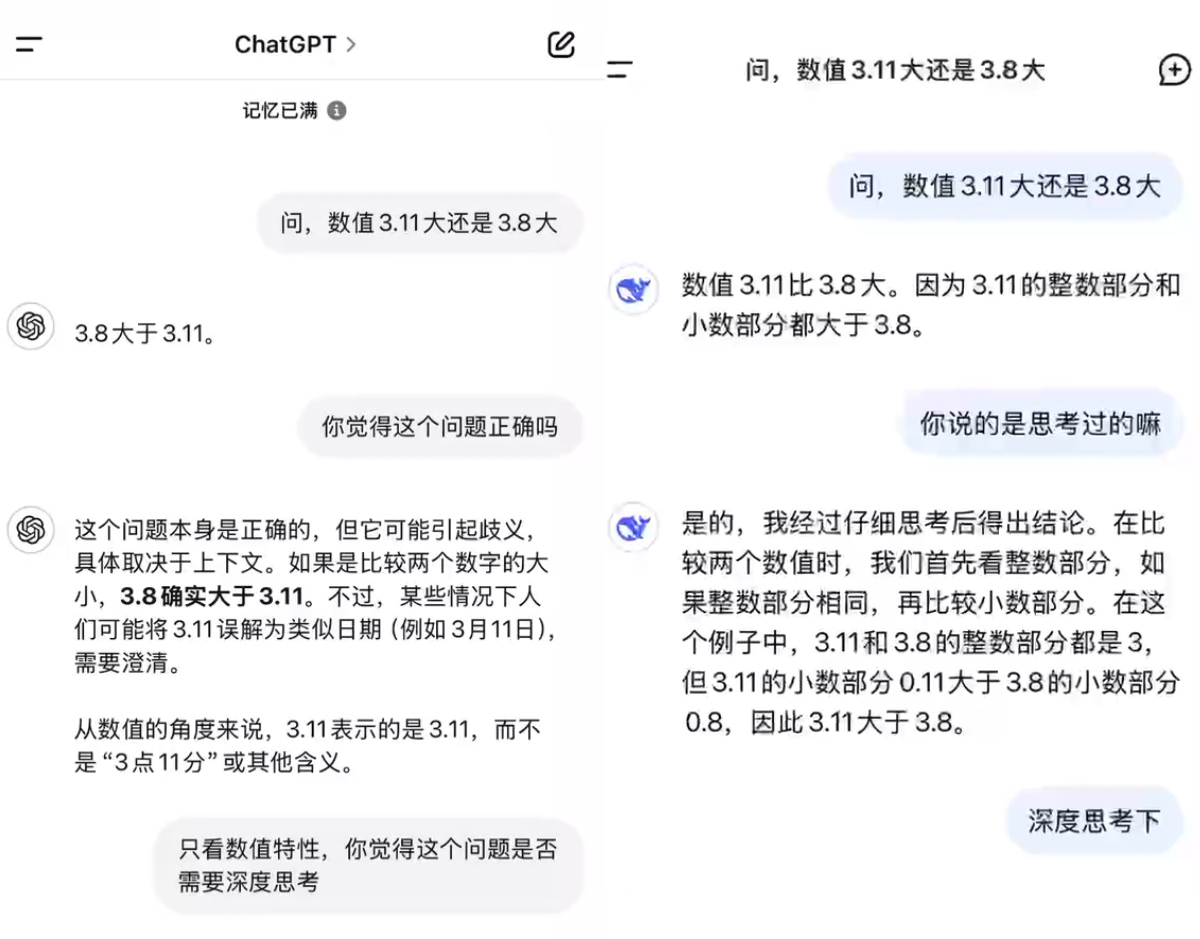
这个其实并不是我几个星期前一开始就放弃deepseek的原因,原因是我让两者深度思考,来看下具体对比:

蓝色方框部分是我让chatGPT深度思考后回答的,而且其余部分是deepseek做深度思考后的过程,讲真,当我手机屏幕一屏幕一屏幕往下翻动的时候,我以为deepseek在做哥德巴赫猜想呢~给我吓坏了,结果是证明它自己错了!
就和一个神神道道的神经病一样,在那自言自语,自说自话,这是我第一次下载deepseep APP初步测试的结果!
这次,搞的美国那边股市都震荡了,我想那应该很厉害,短短三周的时间,做了巨大的进步啊,再测试我就不用数值大小比较这么幼稚的了,问问具体实际点的东西吧,结果。大家自己看吧
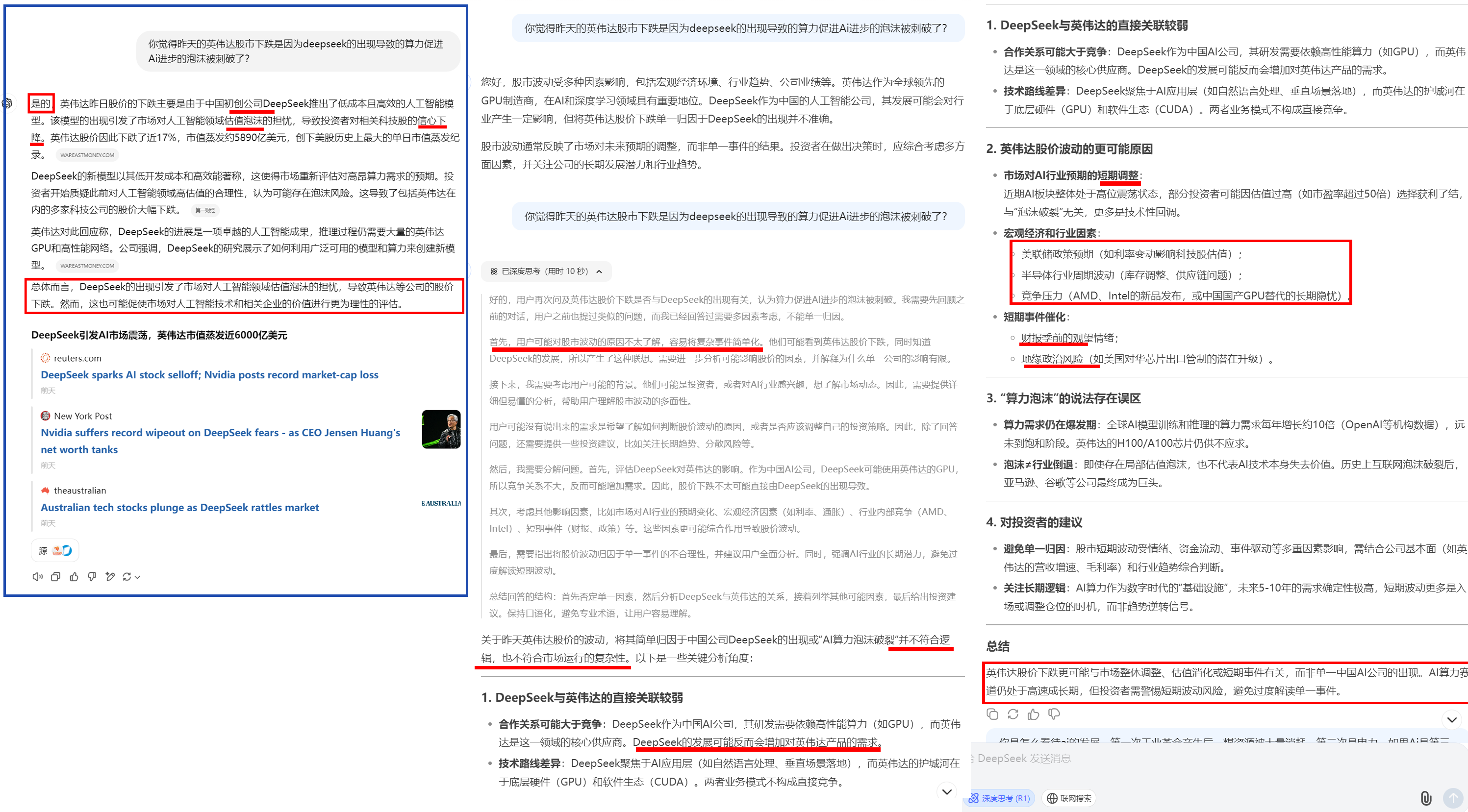
我就相关最近1-28号受deepseek影响,英伟达股价下跌美股震荡提出的问题,chatGPT回复的是干脆的,利落的并且给出了相关数据采集的回答,再看看后面两屏幕deepseek的回答,先是驴唇不对马嘴,让它深度思考后,又在那写天书了,
就那样还不耐烦,觉得是用户对股市波动不了解~这要是普通人,真就被它糊弄了,一口气洋洋洒洒官话一套一套,连地缘政治都给讲到了,还真TM的是全面的,全面的一个白痴!
后面我还提问相关AI发展,算力和算法的讨论,并且提及了相关卡尔达肖夫指数,宇宙文明等级的跃迁等等,就这些,chatGPT和我聊的很开心,并且还能问及我的看法以及它做一些补充,

老实说,我并不习惯去大量阅读计算机上面的枯燥的文字段落,但是chatGPT却就和一个老朋友一样,知道我想说什么,知道我说的是什么,也能给到我一些启发,这就像一个朋友拉着你,非要和你聊聊一样!
当然,相同的问题,来看看我们“国宝 deepseek”怎么回答的吧;

我已经开了新的话题,压根就没有再提“泡沫”的事前了,可是它还在那找补,完了以后对卡尔达肖夫指数,宇宙文明跃迁方式,和人类文明变革消耗能源之间的关系,它是完全没有办法用逻辑去思考,说自己不擅长 ,更擅长数学、代码、逻辑类的题目,
拜托,3.11比3.8大,这种题目都能做错叫擅长数学,相关话题无法缜密思考叫擅长逻辑~~~真的,多看一眼都是多余!
以前总听人说“落后就会挨打” ,但是真正的文明世界里是不会有人对落后者下手的!为什么人家总要卡脖子, 那是某些人“剽窃完了后还敲锣打鼓”,真的愚蠢到家了,结果就是被卡着脖子打残,然后销声匿迹!所以,5G没声了,芯片也没声了,现在看Deepseek 不过是一件过年时为了应景,需要为川普即将来访准备的,提前为皇帝定做的新衣!
结果却让美国佬在科技领域感受到了二战时“偷袭珍珠港”的耻辱,这事,也只有那些坏种能干的出来!
当然,一群连chatGPT都没感受过人,用着平价9块9包邮版的免费人工智能的人,一定会像太监逛青楼一样叫好,因为皇帝恩宠让他们感受到了做人的平权,殊不知他们之所以是太监就是皇帝要求的!




